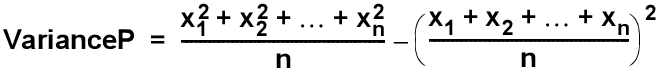
필드에 공백이 아닌 연속된 값으로 표시되는 모집단의 분산을 반환합니다.
VarianceP(필드 {; 필드...})필드 - 관련 필드, 반복 필드 또는 반복되지 않는 필드 세트 또는 필드, 반복 필드 또는 반복되지 않는 필드 세트를 반환하는 표현식.
괄호{ }의 매개 변수는 옵션입니다.
숫자
FileMaker Pro 7.0
모집단 분산의 분산은 얼마나 분산되어 있는지 측정합니다. 필드는 다음 중 하나일 수 있습니다.
•반복 필드 (반복할 필드).
•이 레코드가 포털에 표시 여부와 관계없이 (테이블::필드)에서 지정한 일치되는 관련 레코드의 필드.
•(필드1;필드2;필드3...)에서 여러 반복되지 않는 필드 레코드.
•결과가 최소한 동일한 수로 반복되는 반복 필드에서 반환되는 경우 레코드 (반복할 필드1;반복할 필드2;반복할 필드3)에서 반복 필드의 해당 반복.
•(테이블::필드1;테이블::필드2;...)에서 지정된 첫 번째로 일치되는 레코드의 여러 필드. 다른 테이블 (테이블 1::필드 A;테이블 2::필드 B...)의 필드를 포함할 수 있습니다.
포털은 점수에 관련 값 5, 6, 7, 8을 표시합니다.
VarianceP(테이블::점수)는 1.25를 반환합니다.
아래 예제에서
•필드1은 값이 1과 2인 두 번의 반복을 포함합니다.
•필드2는 값이 5, 6, 7, 8인 네 번의 반복을 포함합니다.
•필드3는 값이 6, 0, 4, 4인 네 번의 반복을 포함합니다.
•필드4는 값이 3인 한 번의 반복을 포함합니다.
VarianceP(필드4)는 단일 값의 분산이 정의되지 않기 때문에 오류가 발생합니다.
VarianceP(필드1;필드2;필드3)는 계산이 반복 필드인 경우 4.66666666..., 6.22222222..., 2.25, 4를 반환합니다.
시험을 치르는 두 학급의 학생이 있습니다. 학급 1의 점수는 70, 71, 70, 74, 75, 73, 72이며 학급 2의 점수는 55, 80, 75, 40, 65, 50, 95입니다. 각 학급의 모집단 분산은 다음과 같습니다.
학급 1: 3.26530612...
학급 2: 310.20408163...
학급 1의 점수가 보다 조밀하기 때문에 학급 1의 모집단 분산이 학급 2의 모집단 분산보다 훨씬 낮습니다.